")
Sample size calculation for eye surveys: a simple method
Related content
This article concerns eye surveys designed to obtain and examine an unbiased random sample of individuals from a defined population, so that the prevalence of various conditions (such as visual impairment and serious eye disorders) in the population may be estimated with adequate precision.
The sample size must be determined before the survey is carried out and as early as possible in the planning stage. Calculation of the required sample size is not an exact procedure. The computed sample size should be regarded as an approximate minimum number of persons that should be selected and examined. Deciding on a sample size is an exercise in balance between cost (resources needed) and the precision of the prevalence estimates that are to be made. The survey should not be carried out unless the sample size is judged to be large enough to give the minimum required precision.
Sample Size Calculation
To calculate the required sample size, the following have to be specified:
a) Maximum random sampling error that can be accepted (E), under various assumed values of the actual prevalence (P) of the condition in the population.
b) Probability that E is not exceeded. This is usually set at 0.95, indicating that 95% confidence limits are to be calculated when estimating P. We shall assume that the planned survey intends to report prevalence with 95% confidence limits.
c) The likely design effect (W ), which depends upon the method of sampling, and may be regarded as a penalty for deviating from simple random sampling.
d) The population size (n).
The approximate (minimum) sample size can then be computed using the following simplified equations:
The equations in the box take into account the sampling fraction n/N, and the design effect W , in an appropriate way so that ‘silly’ results are avoided when the sampling fraction and W are both large. Under these conditions, some sample size calculation software such as the EPITABLE module of EPI INFO: version 6.04a (otherwise an excellent software package) may give sample sizes that are larger than the population size!
A = 3.8416 PQW
n = A / (E2 + (A/N))
where:
n = minimum sample size required (approximate)
P = assumed population prevalence, in %
Q = 100 – P
E = maximum acceptable random sampling error, in %
W = the likely design effect
n = population size
(The value 3.8416 is 1.962, corresponding to 95% probability of not exceeding E)
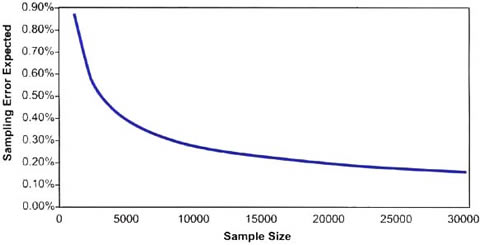
Figure 1. Relationship between sample size and expected sampling error (E), assuming a population prevalence of 2%, population size 1 million, and simple random sampling
Specifying E and P
The precision needed to estimate a prevalence in a population depends on the prevalence itself. For example, if the expected prevalence of blindness in the population is, for example, around 1%, then an estimate of 1% ± 0.25% may be acceptable, whereas an estimate of 1% ± 5% is useless. Thus, 5% may be an acceptable sampling error only if the prevalence is say 10% or more. For lower prevalence of perhaps 1.5% to 0.5%, the maximum acceptable sampling errors are much smaller, e.g., 0.25% or less. Surveys of rare diseases require larger sample size primarily because large sampling errors cannot be accepted. Insisting on small sampling errors, i.e., wanting high precision, will require much larger sample size. For example, to reduce the sampling error from 0.3%, to 0.2%, the sample size may have to be more than doubled. Fig. 1 shows the relationship between the expected sampling error and sample size for a particular situation.
Sample size(s) should be calculated to give adequate precision for estimating the least prevalent condition that is of primary interest. This, however, should be done with due regard to the main objectives of the survey.
The term PQ in the equation above is a measure of variability in the population. Maximum variation exists when P=50%.
The higher the variation, the larger the required sample size, ceteris paribus. This effect on sample size, however, is more than compensated for by accepting relatively large random sampling errors. Therefore, in general, high prevalence conditions require smaller sample sizes.
The design effect W
The random sampling errors tend to be higher in cluster random sampling compared to simple random sampling. The simple random sampling method involves random selection of individual persons from a complete list of all persons in the population. The complete list (sampling frame), which should contain all and only all the eligible members of the population, may be difficult to obtain or impossible to construct. Furthermore, even if a sampling frame was available and simple random sampling used, the selected individuals may be scattered over a large area, requiring excessive travel by the survey team with high cost. In most eye surveys a cluster random sampling method is used whereby a number of so called Primary Sampling Units (PSUs, e.g., administrative areas, communities, villages, etc.) are first selected from a list of all eligible PSUs, then sub-sampling is carried out within each selected PSU in one or more stages. A relatively simple and popular method used in many eye surveys in rural populations is a 2-stage cluster random sampling technique. This involves random selection of a number of communities (first-stage units or PSUs) from a complete list of all eligible communities, then drawing a random sample of individuals from each selected community.
In general, for a given sample size, cluster random sampling schemes with many small PSUs and no more than 2 sampling stages give more precise results (lower sampling errors) compared to schemes that have few but large PSUs or involve many stages of sampling. In addition, if the eye condition of interest is highly clustered in small pockets within the population (e.g., trachoma), then much larger sampling errors should be expected from cluster random sampling methods.
The design effect is a ratio of two variances (measures of sampling error) V1/V2, where V1 is the variance when a cluster random sampling method has been used, and V2 is calculated assuming a simple random sampling method. The design effect = 1, when the sampling method used is equivalent to simple random sampling, and is usually (but not always) higher than 1, when a cluster random sampling method has been used. Thus, the design effect may be regarded as a penalty; a ‘multiplier’ for sample size; when a cluster random sampling method is to be used.
In practice, when computing sample size, it is difficult to know what the design effect might be. Experience from surveys in the past 10 years or so suggest that for estimating prevalence of blindness, or of any other condition which has a fairly uniform distribution in the population, it is safe to assume a design effect of say 1.5, (W =1.5), provided that a fairly simple sampling method is to be used, such as single-stage cluster random sampling with average cluster size of about 300-400 persons. For estimating prevalence of active inflammatory trachoma or any other condition that might be highly clustered, much larger design effects (5 or more) should be specified.
Gain in precision from stratification
Stratification in sampling surveys involves sub-dividing the population into 2 or more distinct groups (strata), covering the entire population, then drawing a sample (usually a proportional sample) from every stratum using simple or cluster random sampling methods. This is usually done in the hope that sampling errors might be reduced, and/or to obtain better geographic coverage of the population. If stratification is to reduce sampling errors substantially, then the strata should be defined in such a way that the difference in prevalence (or risk of the condition of interest) between the strata is maximised. This is hardly ever achieved.
Appropriate stratification of the population may reduce sampling errors, and therefore allow smaller sample size for any given desired precision in estimating prevalence. The gains in precision, however, are not likely to be substantial in most eye survey situations. In calculating sample size for eye surveys, it is safer to ignore the possible gain that might arise from stratification. There are two main reasons for this suggestion. First, the more complex equations demand that fairly accurate assumptions are made about the prevalence in each stratum, and about the stratum-specific design effects. These are usually difficult and often virtually impossible to foretell with any confidence. Indeed, if such accurate predictions could be made, the survey would be redundant. Second, the predicted design effect tends to be set too low, so that ignoring the possible gains from stratification should, to some extent, compensate for the too hopeful prediction of the design effect. Accordingly, the simplified equation proposed above does not take into account any possible gains from stratification.
Worked examples of calculating sample size
The primary objective of an eye survey is to estimate the prevalence of blindness and of low vision in a rural population of 0.5 million. A single-stage cluster random sampling method is proposed, with an average cluster size of ~ 250 persons. The population is to be divided into 3 main strata, according to size of the rural communities, and a proportional sample drawn from each stratum.
Sample size required for estimating prevalence of blindness:
Scenario 1:
If expected prevalence = 1%,
then maximum acceptable sampling error
E = 0.25% Expected design effect W = 1.5
A = 3.8416 × 1 × 99 × 1.5 = 570.48
n = 570.48 / (0.252 + (570.48 / 500000)) = 8964
Therefore, a sample size of about 9000 is required.
Scenario 2:
If expected prevalence = 1%,
then maximum acceptable sampling
error E = 0.25%
Expected design effect W = 2.0
A = 3,8416 × 1 × 99 × 2 = 760.64
n = 760.64 / (0.252 + (760.64 / 500000)) = 11881
Therefore, a sample size of about 11900 is required, if the design effect turns out to be as high as 2.0. A compromise would be to aim for a sample size of at least 10500 persons.
Choosing a sample size
Many scenarios should be tried before a final choice is made. For example, if the sample size is fixed at 8000 because of limited resources, and the design effect turns out to be 2.0, what precision will the estimate have? This may be answered by setting W=2.0, and increasing E in small steps until a sample size of around 8000 is reached. The process is easy and quick when the equation is incorporated into a computer spreadsheet or other suitable program. Alternatively, the following equivalent equation may be used, to estimate E for any given sample size n:
E = 1.96 ((PQW/n) (1-f))0.5
where f is the sampling fraction n/N, and may be ignored if it is very small.
The cost implications of the larger sample sizes should be carefully weighed against the gains in precision that they offer, before a final decision is made. Clearly, sample size calculation should not be left to a pure statistician, working away from the survey team. It should be carried out by the survey team, with help from a statistician if necessary.
Further Reading
More detailed discussion of complex sampling methods, including the optimal size of sampling units in various stages of multistage sampling, can be found in ‘Sampling Techniques’ by William G. Cochran.1
Reference
1 Cochran WG. Sampling Techniques. 3rd Ed., Wiley, New York, 1977.